project Betfair, part 7
Table of Contents
Introduction
Previously on project Betfair, we ran the production market-making CAFBot in Scala, got it working, made some money, lost some money and came back with some new ideas.
Today, we'll test those ideas, look at something that's much more promising and learn a dark truth about timezones.
Sorry this took a bit too long to write, by the way, I've been spending some time working on Kimonote to add email digests to streams. The idea is that given some exporters from streams (e-mail, RSS (already works), Facebook, Twitter etc) with varying frequencies (immediately or weekly/daily digests) as well as some importers (again RSS/Twitter/Facebook/other blogging platforms) a user could create their own custom newsletter and get it sent to their mailbox (push) instead of wasting time checking all those websites (pull), as well as notify their social media circles when they put a new post up anywhere else. None of this works yet, but other features do — if you're interested, sign up for the beta here!
Shameless plug over, back to the world of automated trading goodness.
CAFBotV2 with wider spreads
Remember how in the real-world greyhound market the bot managed to have some of its bets matched despite that they were several ticks away from the best back and lay? I realised I never really tested that in simulation: I started from making the market at the top of the order book and kind of assumed that further away from there matching would never happen. Looks like I was wrong (and in fact in part 5 the bot had issues with its bets that were moved away from the current market because of high exposure getting matched anyway).
So I added (backported?) the levelBase parameter from the Scala bot into the research one: recall that it specified how far from the best back/lay the bot should start working before applying all the other offsets (exposure or order book imbalance). Hence at levelBase = 0 the bot would work exactly as before and with levelBase = 1 it would start 1 Betfair tick away from the best back/lay. levelBase = 3 is what was traded live on the greyhound market.
The idea behind this is kind of simple: if the bot still gets its bets matched even if it's far away from the best back/lay, it will earn a higher spread with fewer trades.
So, first, I ran it on our favourite horse market with levelBase = 1.
Results
Horses, levelBase = 1
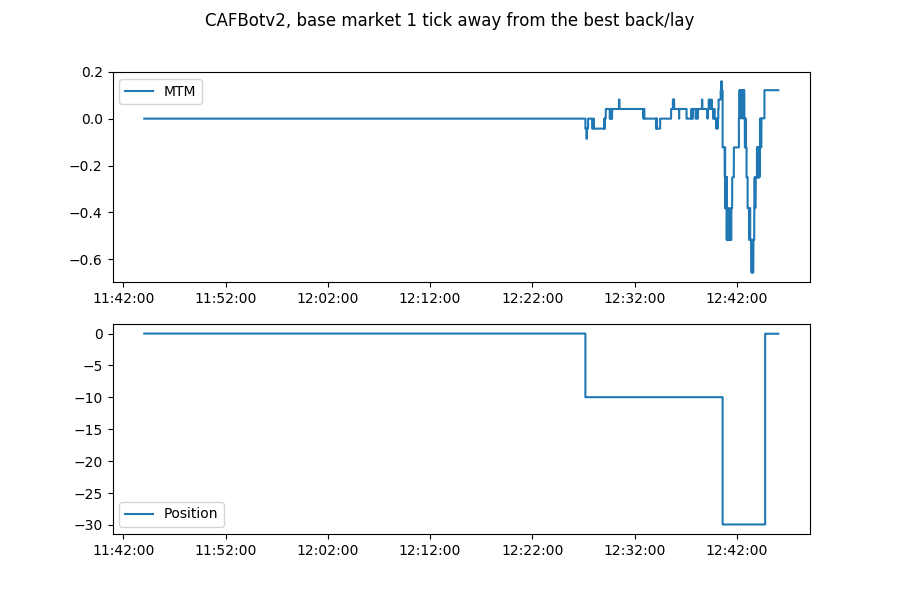
It didn't do well: there were very few matches and so most of the time it just did nothing, trading a grand total of 3 times. This meant that it got locked into an inventory that it couldn't offload.
Let's run it on the whole dataset: though this market didn't work as well, in some other ones matching did happen in jumps larger than 1 tick, so those might be able to offset more liquid markets.
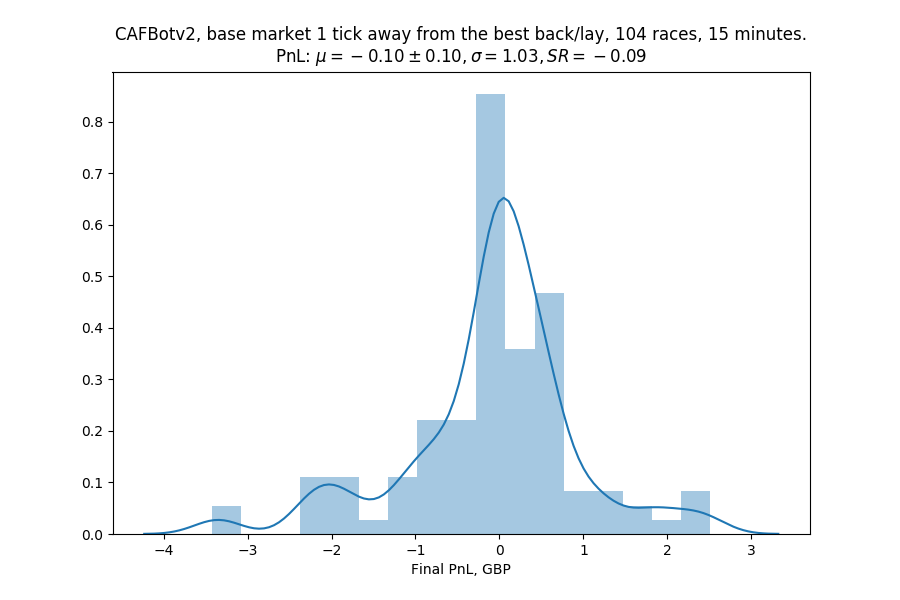
We're tantalizingly close to finally having a PnL of zero (the more observant reader might notice that we could have done the same by not trading at all). Let's see how it would have done on the greyhound markets, which we do know sometimes jump like crazy.
Greyhounds, levelBase = 3
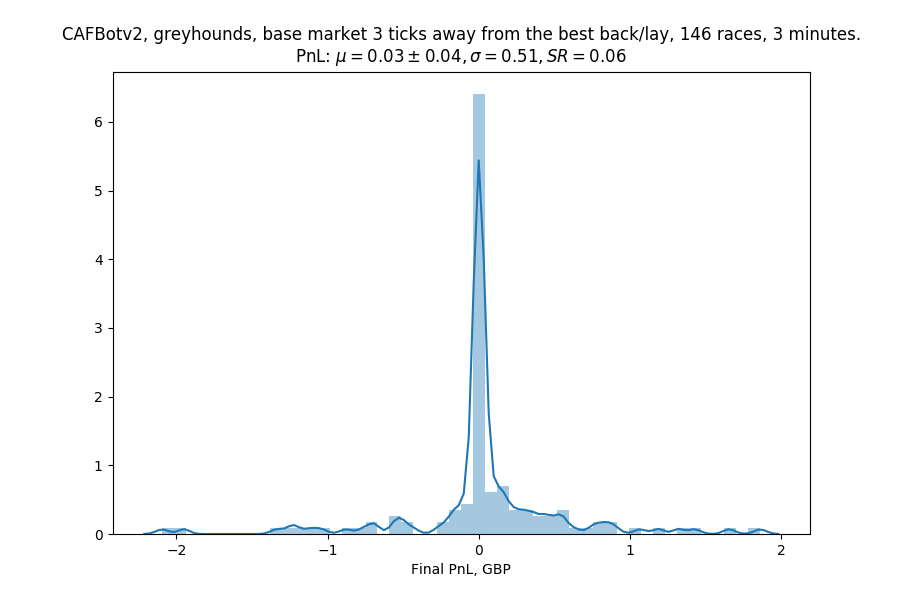
Not very inspiring either. There's a large amount of markets where this wouldn't have done anything at all (since the bets were so far from the best back/lay, they don't ever get hit), and when something does happen, it seems to be very rare, so the bot can't liquidate its position and remains at the mercy of the market.
So while that was a cute idea, it didn't seem to work.
DAFBot
At this point, I was running out of ideas. The issue of the bot getting locked into an inventory while the market was trending against it still remained, so I had to look at the larger-scale patterns in the data: perhaps based on the bigger moves in the market, the bot could have a desired inventory it could aim for (instead of always targeting zero inventory).
Consider this: if we think that the market is going to move one way or another, it's okay for the bot to have an exposure that way and it can be gently guided towards it (by means of where it sets its prices). Like that, the bot would kind of become a hybrid of a slower trading strategy with a market maker: even if its large-scale predictions of price movements weren't as good, they would get augmented by the market making component and vice versa.
Carry?
I tried out a very dumb idea. Remember how in most of the odds charts we looked at the odds, for some reason, trended down? I had kind of noticed that, or at least I thought I did, and wanted to quantify it.
Those odds were always on the favourite (as in, pick the greyhound/horse with the lowest odds 1 hour before the race begins and see how they change). The cause could be that, say, people who wanted to bet on the favourite would delay their decision to see if any unexpected news arrived before the race start, which is the only sort of news that could move the market.
Whatever the unexpected news would be, they would likely affect the favourite negatively: they could be good for any of the other greyhounds/horses, thus making it more likely for them to win the race. Hence it would make sense, if someone wanted to bet on the favourite, for them to wait until just before the race begins to avoid uncertainty, thus pushing the odds down as the race approaches.
So what if we took the other side of this trade? If we were to go long the favourite early, we would benefit from this downwards slide in odds, at the risk of some bad news coming out and us losing money. I guessed this would be similar to a carry trade in finance, where the trader makes money if the market conditions stay the same (say, borrowing money in a lower interest rate currency and then holding it in a higher interest rate currency, hoping the exchange rate doesn't move). In essence, we'd get paid for taking on the risk of unexpected news about the race coming out.
Research: greyhounds
I had first started doing this using my order book simulator, but realised it would be overkill: if the only thing I wanted to do was testing a strategy that traded literally twice (once to enter the position, once to close it), it would be better write a custom scraper from the stream data that would get the odds' timeseries and simulate the strategy faster.
At that point, I realised the horse racing stream data was too large to fit into memory with the new simulator. So I put that on hold for a second and tried my idea on greyhound markets.
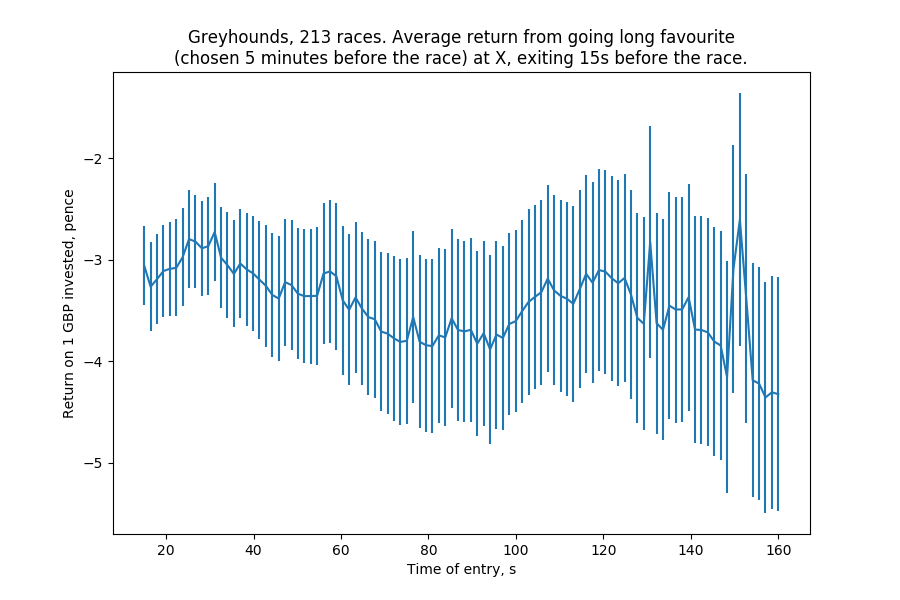
This chart plots, at each point in time before the race, the average return on going long (backing) the favourite and then closing our position 15s before the race begins. In any case, the favourite is picked 5 minutes before the race begins. The vertical lines are the error bars (not standard deviations). Essentially, what we have here is a really consistent way to lose money.
This is obviously because of the back-lay spreads: the simulation here assumes we cross the spread both when entering and exiting, in essence taking the best back in the beginning and the best lay at the end.
Remember this chart from part 4?
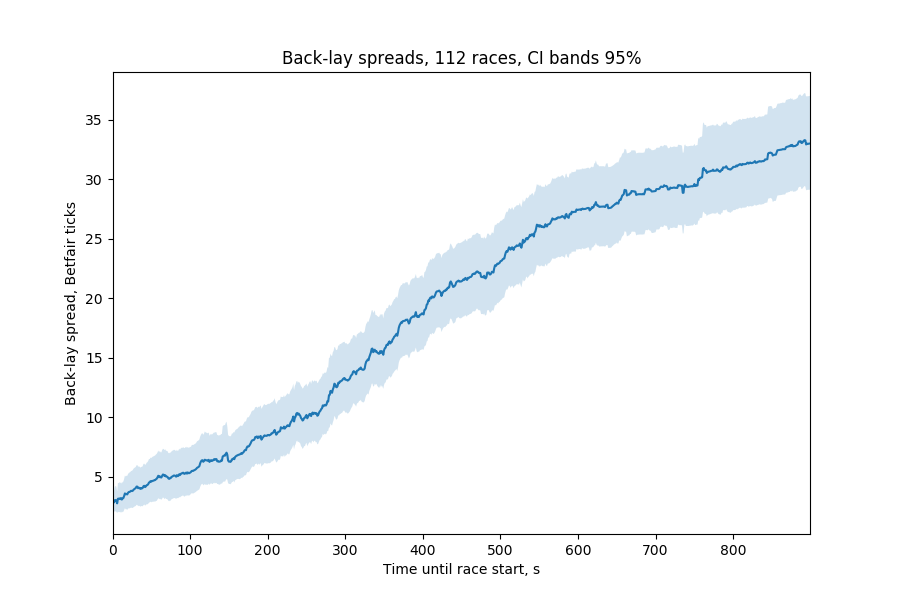
The average spread 120s before a greyhound race begins is about 5 ticks. We had previously calculated that the loss on selling 1 tick lower than we bought is about 0.5%, so no wonder we're losing about 3% of our investment straight away.
What if we didn't have to cross the spread?
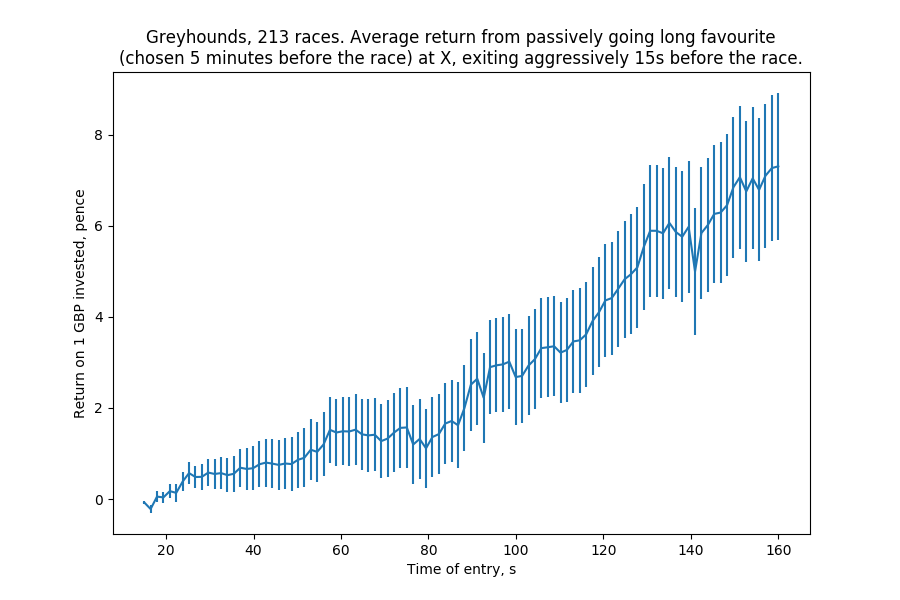
Woah. This graph assumes that instead of backing the runner at the best back, we manage to back it at the current best lay (by placing a passive back at those odds). When we're exiting the position just before the race begins, time is of the essence and so we're okay with paying the spread and placing a lay bet at the odds of the current best lay (getting executed instantly).
The only problem is actually getting matched: since matching in greyhound markets starts very late (as much money gets matched in the last 80 seconds as does before), our bet could just remain in the book forever, or get matched much closer to the beginning of the race.
But here's the fun part: this graph doesn't care. It shows that if the bet is matched at whatever the best lay was 160 seconds before the race, on average this trade makes money — even if the actual match happens a minute later. If the bet doesn't get matched at all, the trade simply doesn't happen.
This does assume that the performance of this strategy is independent of whether or not the bet gets hit at all, but if that's not the case, we would have been able to use the fact that our bet got hit as a canary: when it gets hit, we know that being long this market is a good/bad thing and adjust our position accordingly.
Implementation in Scala
With that reasoning, I went to work changing the internals of Azura to write another core for it and slightly alter the way it ran. The algorithm would be:
- Run with parameters: market, favourite selection time, entry start time, entry end time, exit time (all in seconds before the race start), amount to bet.
- Subscribe to the market/order streams, get the market suspend time from the Betfair API
- At favourite selection time: inspect our local order book cache, select the runner with the lowest odds
- At entry start time: place a passive back at the current best lay odds of the given amount on the favourite.
- At entry end time: cancel remaining unexecuted orders.
- At exit time: if we have a position (as in our entry order got hit), unwind it aggressively.
I called the new core DAFBot (D stands for Dumb and what AF stands for can be gleaned from the previous posts). I wanted to reuse the idea of polling a strategy for the orders that it wished to offer and the core being stateless, since that would mean that if the bot crashed, I could restart it and it would proceed where it left off. That did mean simple actions like "buy this" became more difficult to encode: the bot basically had to look at its inventory and then say "I want to maintain an outstanding back bet for (how much I want to buy - how much I have)".
Finally, yet another Daedric prince got added to my collection: Sheogorath, "The infamous Prince of Madness, whose motives are unknowable" (I had given up on my naming scheme making sense by this point), would schedule instances of Azura to be run during the trading day by using the Betfair API to fetch a list of greyhound races and executing Azura several minutes before that.
Live trading
I obviously wasn't ready to get Sheogorath to execute multiple instances of Azura and start losing money at computer speed quite yet, so for now I ran the new strategy manually on some races, first without placing any bets (just printing them out) and then actually doing so.
The biggest issue was the inability to place bets below £2. I had thought this wouldn't be a problem (as I was placing entry bets with larger amounts), but fairly often only part of the offer would get hit, so the bot would end up having an exposure that it wasn't able to close (since closing it would entail placing a lay bet below £2). Hence it took some of that exposure into the race, which wasn't good.
Timing bug?
In addition, when testing Sheogorath's scheduling (by getting it to kick off instances of Azura that didn't place bets), I noticed a weird thing: Sheogorath would start Azura one minute later than intended. For example, for a race that kicked off at 3pm, Azura was supposed to be started 5 minutes before that (2:55pm) whereas it was actually executed at 2:56pm.
While investigating this, I realised that there was another issue with my data: I had relied on the stream recorder using the market suspend times that were fetched from Betfair to stop recording, but that might not have been the case: if the greyhound race started before the scheduled suspend time, then the recording would stop abruptly, as opposed to at the official suspend time.
Any backtest that counted backwards from the final point in the stream would kind of have access to forward-looking information: knowing that the end of the data is the actual suspend time, not the advertised one.
Hence I had to recover the suspend times that the recorder saw and use those instead. I still had all of the logs that it used, so I could scrape the times from them. But here was another fun thing: spot-checking some suspend times against Betfair revealed that they sometimes also were 1 minute later than the ones on the website.
That meant the forward-looking information issue was a bigger one, since the recorder would have run for longer and have a bigger chance of being interrupted by a race start. It would also be a problem in horse markets: since those can be traded in-play, there could have been periods of in-play trading in my data that could have affected the market-making bot's backtests (in particular, everyone else in the market is affected by the multisecond bet delay which I wasn't simulating).
But more importantly, why were the suspend times different? Was it an issue on Betfair's side? Was something wrong with my code? It was probably the latter. After meditating on more logfiles, I realised that the suspend times seen by Azura were correct whereas the suspend times for Sheogorath for the same markets were 1 minute off. They were making the same request, albeit at different times (Sheogorath would do it when building up a trading schedule, Azura would do it when one of its instances would get started). The only difference was that the former was written in Python and the latter was written in Scala.
After some time of going through my code with a debugger and perusing documentation, I learned a fun fact about timezones.
A fun fact about timezones
I used this bit of code to make sure all times the bot was handing were in UTC:
def parse_dt(dt_str, tz=None):
return dt.strptime(dt_str, '%Y-%m-%dT%H:%M:%S.%fZ').replace(tzinfo=pytz.timezone(tz) if tz else None)
m_end_dt = parse_dt(m['marketStartTime'], m['event']['timezone'])
m_end_dt = m_end_dt.astimezone(pytz.utc).replace(tzinfo=None)
However, timezones change. Since pytz.timezone doesn't know the time of the timezone its argument refers to, it looks at the earliest definition of the timezone, which in the case of Europe/London is back in mid-1800s. Was the timezone offset back then something reasonable, like an hour? Nope, it was 1 minute.
Here's a fun snippet of code so you can try this at home:
In[4]:
from datetime import datetime as dt
import pytz
def parse_dt(dt_str, tz=None):
return dt.strptime(dt_str, '%Y-%m-%dT%H:%M:%S.%fZ').replace(tzinfo=pytz.timezone(tz) if tz else None)
wtf = '2017-09-27T11:04:00.000Z'
parse_dt(wtf)
Out[4]: datetime.datetime(2017, 9, 27, 11, 4)
In[5]: parse_dt(wtf, 'Europe/London')
Out[5]: datetime.datetime(2017, 9, 27, 11, 4, tzinfo=[DstTzInfo 'Europe/London' LMT-1 day, 23:59:00 STD])
parse_dt(wtf, 'Europe/London').astimezone(pytz.utc)
Out[6]: datetime.datetime(2017, 9, 27, 11, 5, tzinfo=[UTC])
And here's an answer from the django-users mailing group on the right way to use timezones:
The right way to attach a pytz timezone to a naive Python datetime is to call
tzobj.localize(dt). This gives pytz a chance to say "oh, your datetime is in 2015, so I'll use the offset for Europe/London that's in use in 2015, rather than the one that was in use in the mid-1800s"
Finally, here's some background on how this offset was calculated.
Recovery
Luckily, I knew which exact days in my data were affected by this bug and was able to recover the right suspend times. In fact, I've been lying to you this whole time and all of the plots in this blog series were produced after I had finished the project, with the full and the correct dataset. So the results, actually, weren't affected that much and now I have some more confidence in them.
Conclusion
Next time on project Betfair, we'll teach DAFBot to place orders below £2 and get it to do some real live trading, then moving on to horses.
As usual, posts in this series will be available at https://kimonote.com/@mildbyte:betfair or on this RSS feed. Alternatively, follow me on twitter.com/mildbyte.
Interested in this blogging platform? It's called Kimonote, it focuses on minimalism, ease of navigation and control over what content a user follows. Try the demo here or the beta here and/or follow it on Twitter as well at twitter.com/kimonote!