Generating image embeddings on a GPU with LLaVA and llama-cpp-python
Table of Contents
Introduction
Everyone nowadays (well, everyone who's experimented with LLMs) knows about text embeddings, which is, after tokenization, a second stage of an LLM processing some text. The cool part about embeddings is that the output of an embedding layer is a vector that's semantically meaningful. So, if I have two embedding vectors that are close to each other, the texts that produced them are also similar to each other.
In Python, with the llama-cpp-python library that uses the llama.cpp library, it's simple enough to generate a text embedding:
=
return
=
=
Well, the not simple part was getting llama.cpp to compile on my Windows machine with CUDA support so that this can run on my GPU instead of a CPU. That's a whole blog post in of itself and maybe I'll write it someday.
The model (ggml-model-q5_k.gguf) is from https://huggingface.co/mys/ggml_llava-v1.5-7b because this is really a post about LLaVA.
LLaVA
Now, you can do something similar with images. The CLIP vision encoder can take an image and turn it into an embedding (a vector) that represents its semantic meaning. Based on this, some researchers built LLaVA by essentially wiring the vision encoder to a large language model (Vicuna):

There are two moving parts here: the projection matrix and the language model itself.
What is the projection matrix? Well, since the encoded vector is expressed in terms of CLIP's "semantic space", we need to "translate" it to LLM's space. We do that by multiplying that vector by a projection matrix (this is also called "feature alignment"). The first stage of the training is about finding a projection matrix that does this the best. They do it by using a subset of the CC3M dataset of images and captions. My understanding is, it works like this:
- Encode all images (you now have a set of image embedding vectors)
- Embed all image descriptions using Vicuna (you now have a set of text embedding vectors)
- Optimize the matrix W such that using it to transform the CLIP-encoded image vectors brings them as close to the embedded descriptions as possible.
The second stage of the training is about fine-tuning both the matrix and the language model. The training data for this phase is 158k sets of instructions, images and responses (for example, "What potential risks could this scenario indicate?" - "The scenario in the image shows one airplane flying over the airport runway with its landing gear down while another plane is parked on the runway. This situation might indicate potential risks related to air traffic control and airport runway management. [...]").
We add the encoded and projected image and the instruction to the model's context and train it to produce the expected response.
Getting the image embedding with llama-cpp-python
So, it looks like going through this process makes the basic CLIP embeddings "smarter": we not only train a matrix to project the original vector into LLM's space, but also train it in the second stage together with the rest of the LLM to give expected language responses.
It would be useful to get our hands on that embedding. Besides being able to do semantic image search (by taking an embedding of the query and finding the image vectors that are closest to it based on cosine similarity), it would also enable things like discovering image cluster or automatic tagging.
There's a recent blog post doing something similar, but it does it in a different way, by using LLaVA with a text prompt to generate the description of the image and then using an LLM to generate an embedding of that description. I felt like that would discard some of the information in the original image embedding and would take more time (instead of just processing the image into an embedding, we'd do that and process the instruction, run the LLM to get the response, process the response into an embedding again).
First, let's get the model. I downloaded it from a link on the original llama.cpp pull request adding LLaVA support
There are two files:
ggml-model-q5_k.gguf: the actual LLMmmproj-model-f16.gguf: the CLIP encoder and the projection matrix
After some digging around the llama.cpp and llama-cpp-python codebase, I managed to come up with this code snippet:
# Important, otherwise embeddings seem to leak across different
# invocations of get_image_embedding
=
=
=
=
=
=
=
=
# Write the image represented by embed into the llama context
=
assert >=
=
# Get the embedding out of the LLM
=
=
return
=
=
=
Experiment 1: image-to-image similarity
Let's take it for a spin and get some fresh memes from imgur.com:

cat

football (not that fresh but good)

firetruck

microsoft
Compute the embeddings and get their cosine similarity matrix:
=
return /
=
=
=
(this takes about 300ms/image on my GPU)
In this matrix, the position at row, col denotes how similar the image row is to the image col. Let's visualize it:
=
=
=
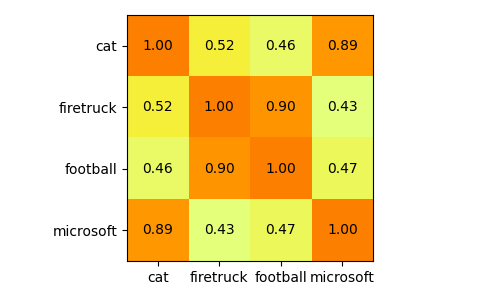
Interestingly enough, it thinks that the Microsoft meme is very similar (0.89 cosine similarity) to the cat meme. Perhaps it's because they use the same font and a similar layout?
Experiment 2: query-to-image similarity
Now let's come up with some search queries that either describe what's happening in the image, mention the text in the image or try and describe the image in a roundabout way:
=
=
=
=
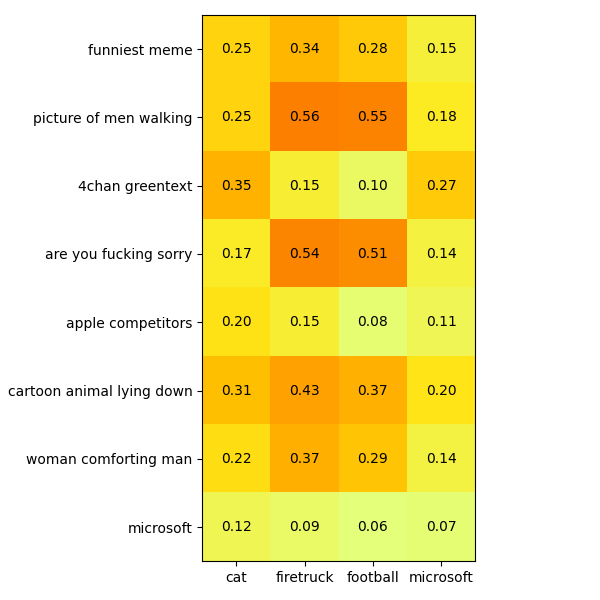
This is kind of fun.
- "Are you fucking sorry" is close to the actual 4chan greentext with that text verbatim as well as the firetruck meme with the woman comforting a man (I guess he is sorry?).
- The firetruck meme is the funniest one, according to the LLM.
- The actual 4chan greentext isn't identified as a 4chan greentext.
- The Microsoft meme doesn't seem to get hit much. It doesn't match "Microsoft" (which is a string that appears in the image) or "picture of men walking". In fact, it matches "4chan greentext" the most, which is bizarre.
Conclusion
So maybe it doesn't grasp the deep hidden meaning of memes, but it's still pretty cool for a model that can run on a consumer GPU and process several images a second. There's a few other things I want to experiment with. For example, using grammar-based sampling with a JSONSchema to make the LLM describe an image but give a very speficic, computer-parseable response. Imagine wiring this to a camera and getting an alert when someone is at the door, or computing how many cats it sees on the street per day — but without sending data to someone else's server.
Yeah, it's been four years since my last blog post. Since then, I ran and sold a startup and didn't do much else. It's nice to have a life again.